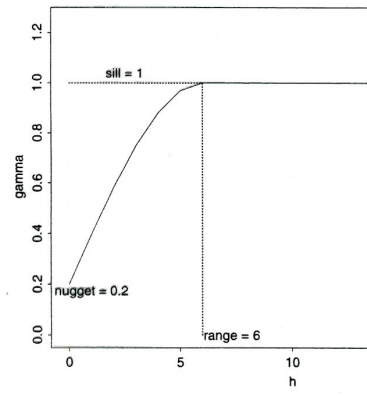
Set of models and tools used for statistical analysis of continuous data
Nature of data:
- Measured at a spatial location
- Number of sampled points are limited
- Constitutes of errors, as such predictions results should also have uncertainity information
Geostatistical analysis goal is to predict values where no data have been collected