Lecture 11: Emerging Trends: NoSQL Databases
Spatial Database Systems
J Mwaura
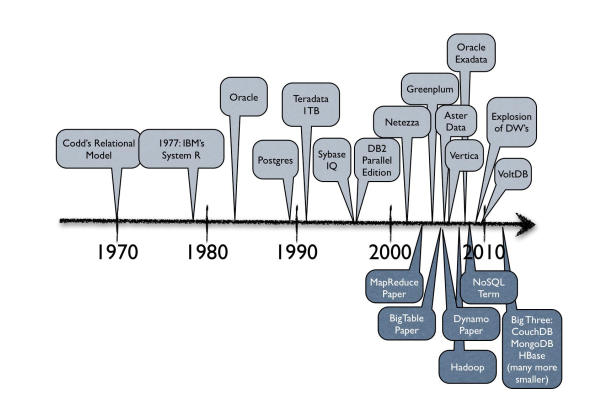
Brief History of Databases
Benefits of Relational Databases
Designed for all purposes
ACID
Strong consistancy, concurrency, recovery
Mathematical background - set theory
Standard Query language (SQL)
Lots of tools to use with i.e. Reporting services, entity frameworks
NoSQL why, what and when?
Era of distributed computing
...but relational databases were not built for distributed applications
Because...
Joins are expensive
Hard to scale horizontally
Impedance mismatch occurs
Expensive (product cost, hardware, Maintenance)
NoSQL why, what and when?
Era of distributed computing
...but relational databases were not built for distributed applications
And...
It's weak in:
- Speed (performance)
- High availability
- Partition tolerance
NoSQL why, what and when?
Spread-out of web applications or services handling Big Data
Big data is high-volume, high-velocity and high-variety information assets that demand cost-effective, innovative forms of information processing for enhanced insight and decision making
Sources of Big Data
Mobile use of internet
Cloud computing
Collaboration
IP-based communication
Social media
Video streaming & media distribution
3 V's of Big Data


Usage of big data
Visibility - making big data accessible in a timely fashion to relevant stakeholders
Discover and analyze information - data fusion to generate new information and patterns
Segmentation and customizations - creating highly specific segmentations and tailor products and services. e.g. segmentation of customers
Aid decision making - improve decision making, minimize risks, and unearth valuable insights e.g. Automated Fraud Alert systems in credit card processing
Innovation - innovation of new ideas in form of products and services
Big Data Challenges
Policies and procedures - compliance of data privacy, security, intellectual property and protection of big data
Access to data - access to 3rd parties data can pose a legal, contractual challenge
Technology and techniques - inadequacy of the legacy systems to deal with Big Data & lack of experienced resources in newer technologies
Structure of Big Data - unstructured data such as images, videos, logs etc
Data storage & processing - more memory needs & new analyses algorithms and analytic softwares
Big Data Technologies
- New Storage and processing technologies designed specifically for large unstructured data e.g. mongoDB
- Parallel processing
- Clustering
- Large grid environments
- High connectivity and high throughput
- Cloud computing and scale out architectures
RDBMS Performance

Properties of NoSQL Databases
Provides:
- Easy and frequent changes to DB
- Fast development & data replication is easy
- Large data volumes - focus is on distributed and horizontal scalability
- Schema less - weak or no schema restrictions
- Easy access is provided via an API
- The consistency model is not ACID (instead, e.g., BASE)
Properties of NoSQL Databases
NoSQL avoids:
- Overhead of ACID transactions
- Complexity of SQL query
- Burden of up-front schema design
- DBA presence
- Transactions (it should be handled at application layer)
NoSQL why/when to use?
Data which requires flexible schema
When ACID support is not really necessary
Object-relational impedance mismatch - conceptual and technical difficulties
Need for distributed or scalable application
Logging data from distributed sources
Storing events/temporal data - shopping carts, wish lists etc.
Polyglot persistence i.e. best data store depending on nature of data
NoSQL why/when not to use?
Financial data
Data requiring strict ACID compliance
Business critical data
Schema-less Data Model
In NoSQL Databases
- No schema to consider
- No unused cell
- No data type (implicit)
- Most of considerations are done in application layer
- Data is gathered in an aggregate - document
Aggregate Data Models
NoSQL databases models
- Key-value
- Document
- Column family
- Graph
Each database has its own query language

BASE & CAP Theorem
BASE - Basically Available, Soft state, Eventually consistent - allows replicated computer nodes to temporarily hold diverging data versions and only be updated with a delay
CAP Theorem by Eric Brewer - states that in any massive distributed data management system, only two of the three properties consistency, availability, and partition tolerance can be ensured

but, We need a distributed database system having such feature; Fault tolerance, High availability, Consistency, Scalability
Comparing ACID & BASE
| ACID | BASE |
|---|---|
| Consistency is the top priority (strong consistency) | Consistency is ensured only eventually (weak consistency) |
| Mostly pessimistic concurrency control methods with locking protocols | Mostly optimistic concurrency control methods with nuanced setting options |
| Availability is ensured for moderate volumes of data | High availability and partition tolerance for massive distributed data storage |
| Some integrity restraints (e.g., referential integrity) are ensured by the database schema | Some integrity restraints (e.g., referential integrity) are ensured by the database schema |
Key-value data model
At the hardware level, CPUs work with registers based on this model
Programming languages use the same concept in associative arrays
Simplest database model possible - is data storage that stores a data object as a value for another data object as key
Uses simple command,e.g., SET, GET
SET User:U17547:firstname JohnSET User:U17547:lastname NzueSET User:U17547:email john.nzue@jkuat.netGET User:U17547:email>>john.nzue@jkuat.net
key-value stores do not support any kind of structure, neither nesting nor references
Key-value data model
Use special characters such as colons or slashes
key-value store properties
- There is a set of identifying data objects, the keys
- For each key, there is exactly one associated descriptive data object, the value for that key
- Specifying a key allows querying the associated value in the database
Example: Amazon DynamoDB, Redis
Key-value data model
Data has no required format data may have any format
Data model: (key, value) pairs
Basic Operations: Insert(key,value), Fetch(key), Update(key), Delete(key)
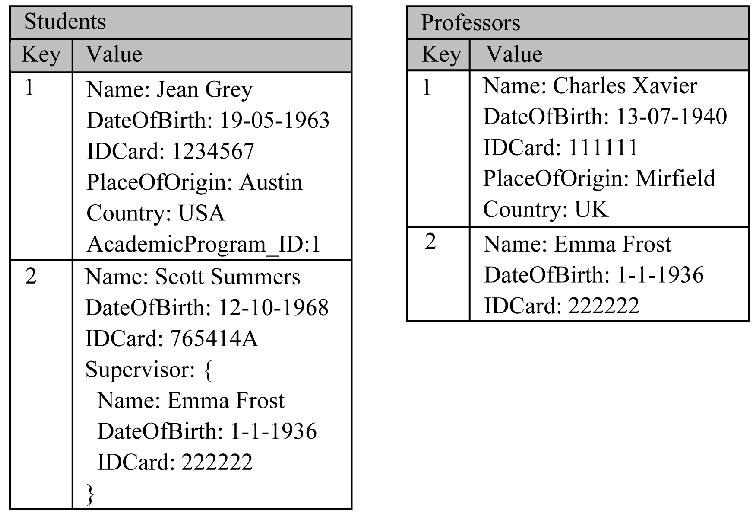
Column family data model
Often, the data matrix needs to be structured with a schema
Column-family stores enhance the key-value concept by providing additional structure
The column is lowest/smallest instance of data
It is a tuple that contains a name, a value and a timestamp
Stores data not in enhanced and structured multidimensional key spaces - column families
Example: Google Bigtable, Cassandra
Column family data model
Column-family store properties
- Data is stored in multidimensional tables
- Data objects are addressed with row keys
- Object properties are addressed with column keys
- Columns of the tables are grouped into column families
- A table's schema only refers to the column families; within one column family, arbitrary column keys can be used
- In distributed, fragmented architectures, the data of a column family is preferably physically stored at one place (co-location) in order to optimize response times
Column family data model

Document Stores model
Pair each key (document ID) with complex data structure known as documents e.g. JSON/BSON format such as {"hello":"world"}
Indexes are done via B-Trees
Document stores are completely schema-free - the demerit of not having schema is the missing referential integrity & normalization
Documents can contain many different key-value pairs, or key-array pairs, or even nested documents
Document store
Document store properties
- It is a key-value store
- The data objects stored as values for keys are called documents; the keys are used for identification
- The documents contain data structures in the form of recursively nested attribute-value pairs without referential integrity
- These data structures are schema-free, i.e., arbitrary attributes can be used in every document without defining a schema first
Document store

Examples: MongoDB, CouchDB, JSON stores
Graph data model
Graph model has a structuring schema as opposed to first 3 models that forgo database schemas and referential integrity for the sake of easier fragmentation (sharding)
Data is stored as nodes & edges, which belong to a node type or edge type, respectively, and contain data in the form of attribute-value pairs
The relationships between data objects are explicitly present as edges, and referential integrity is ensured by the DBMS
Graph data model
Based on Graph Theory
Scale vertically, no clustering
You can use graph algorithms easily
Supports transactions
Observes ACID
Graph data model
Graph data model properties
- The data and/or the schema are shown as graphs or graph-like structures, which generalize the concept of graphs (e.g., hypergraphs)
- Data manipulations are expressed as graph transformations, or operations which directly address typical properties of graphs (e.g., paths, adjacency, subgraphs, connections, etc.)
- The database supports the checking of integrity constraints to ensure data consistency. The definition of consistency is directly related to graph structures (e.g., node and edge types, attribute domains, and referential integrity of the edges)
Graph data model
The advantage of the graph database is the index-free adjacency property - For every node, the database system can find the direct neighbor, without having to consider all edges

Graph data model
Graph data model

Data Warehouse
Business intelligence - decisions making based on facts gathered from the analysis of the available data
Data analysis is often complex - due to heterogeneity, volatility, and fragmentation of the data, cross-application
Business intelligence makes 3 demands on the data to be analyzed
- Integration of heterogeneous data
- Historicization of current and volatile data
- Complete availability of data on certain subject areas
Data Warehouse
Data warehouse - a data warehouse or DWH is a distributed information system with the following properties
Integrated- data from various sources and applications (source systems) is periodically integrated and filed in a uniform schemaRead only- data in the data warehouse is not changed once it is writtenHistoricized- thanks to a time axis, data can be evaluated for different points in timeAnalysis-oriented- all data on different subject areas like customers, contracts, or products is fully available in one placeDecision support- the information in data cubes serves as a basis for management decisions
Steps of Data Warehousing
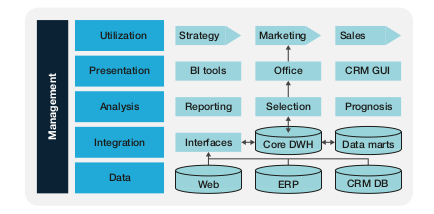
Data Mining Tools
Classification
Selection
Prognosis
Knowledge acquisition
MongoDB
Mongo database properties;
- It is a JSON-style documents
- Provides a Flexible 'Schemas" e.g.
{"author":"mike","text":"..."} change to {"author":"eliot","text":"...","tags":["mongodb"]} - Dynamic indexing & querying
- Atomic update modifiers
- Focus on performance
- Replication
- Auto-sharding
- Many supported platforms/languages
MongoDB
Mongo database is less good at;
- Highly transactionals needs
- Ad-hoc business intelligence
- Problems that require SQL
End of Lecture 11
GIS Database Systems
That's it!
Queries about this Lesson, please send them to:
*References*
- Database Systems: Design, Implementation, and Project Management, Springer.
Albert K W Yeung & G. Brent Hall- Database Systems: Design, Implementation, and Management, 12th ed.
Carlos Coronel & Steven Morris- Database Modeling and Design; Logical Design, 5th ed.
Taby Teorey et.al- Fundamentals of database systems, 6th ed.
Ramez Elmasri & Shamkant B. Navathe
Courtesy of …